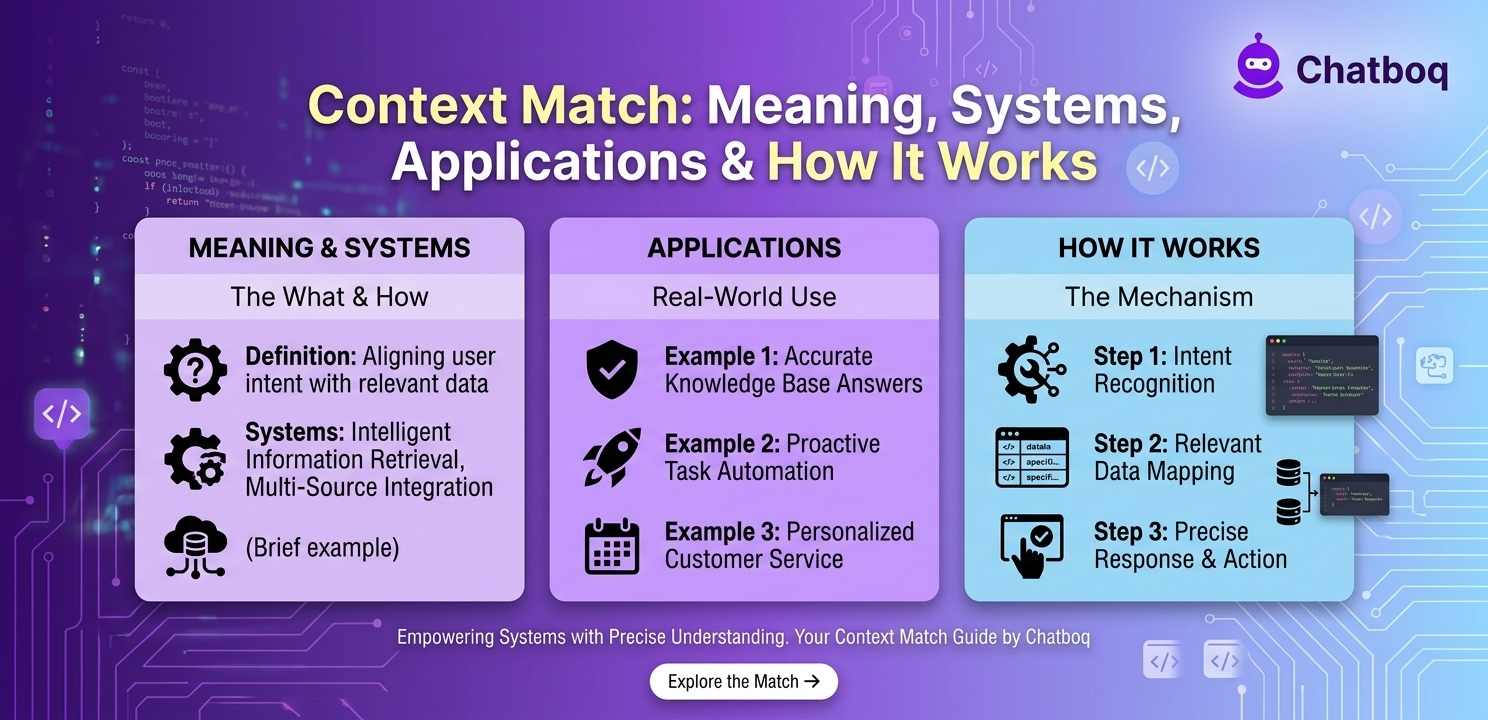
Context matching introduces 8 specific failure modes that exact-match systems do not face: context ambiguity, data quality problems, computational costs, long-context degradation, privacy considerations, bias and contextual errors, context drift, and hallucinated context in AI systems.
Context Ambiguity
Context ambiguity can persist even with sophisticated matching when the surrounding signals themselves are unclear or contradictory, meaning context matching reduces but does not eliminate the underlying ambiguity problem.
This limitation matters because it sets a realistic ceiling on accuracy: no context matching system can resolve a genuinely ambiguous situation that even a human reader would struggle to interpret correctly.
Data Quality Problems
Data quality problems compound directly into matching quality, since a context matching system is only as reliable as the surrounding data it draws on, including session history, metadata, and stored content.
Incomplete, outdated, or poorly structured underlying data produces unreliable context regardless of how sophisticated the matching algorithm itself is, making data quality a prerequisite rather than a secondary concern.
Computational Costs
Computational costs scale meaningfully with the breadth of context considered, since richer context collection and comparison require more processing than simple literal matching across large volumes of content.
This tradeoff forces real-world systems to balance context depth against latency and infrastructure cost, often settling for a practical middle ground rather than maximizing context breadth at any cost.
Long-Context Degradation
Long-context degradation describes the measurable drop in matching accuracy as the amount of context grows beyond what a system can reliably weigh, a known limitation in current large language models.
This means simply supplying more context is not always an improvement, since systems can lose track of earlier information or fail to weigh distant context appropriately once a certain volume is exceeded.
Privacy Considerations
Privacy considerations arise whenever context includes session history or behavioral data, since richer context often means richer personal data being collected, stored, and processed by the matching system.
This tension is central to the shift toward privacy-first contextual advertising models, where context matching is deliberately favored over behavioral tracking specifically to reduce this privacy exposure.
Bias and Contextual Errors
Bias and contextual errors can emerge when training data embeds skewed associations that the matching system then reproduces in its context-based decisions, even without any explicit intent to discriminate.
Because context matching often relies on learned patterns rather than fixed rules, biased patterns in the underlying data can propagate into matching outcomes in ways that are harder to detect than a simple exact-match error.
Context Drift Problems
Context drift occurs when the meaning of surrounding signals shifts gradually over time, causing matches that were once accurate to become stale without any explicit change in the underlying system itself.
This is a particular risk in fast-moving domains where terminology, user behavior, or product catalogs change continuously, requiring ongoing monitoring rather than a one-time matching setup.
Hallucinated Context in AI Systems
Hallucinated context in AI systems describes cases where a model generates context that was never actually present in the source material, a failure mode rarely discussed by competitors despite its direct relevance to RAG reliability.
This is distinct from a simple retrieval failure: the system does not just fail to find relevant context, it fabricates plausible-sounding context that did not exist in any retrieved source.




Leave a Comment
Your email address will not be published. Required fields are marked *
By submitting, you agree to receive helpful messages from Chatboq about your request. We do not sell data.